正在加载今日诗词....
📌 Powered by Obsidian Digital Garden and Vercel
载入天数...载入时分秒... 总访问量次 🎉
载入天数...载入时分秒... 总访问量次 🎉
authors:
Chenyu Wang,Shuo Yan,Yixuan Chen,Yujiang Wang,Mingzhi Dong,Xiaochen Yang,Dongsheng Li,Robert P. Dick,Qin Lv,Fan Yang,Tun Lu,Ning Gu,Li Shang
视频生成模型由于迭代去噪过程,在产生高质量视频的同时,往往需要大量的计算资源和时间,并且这种计算需求会随着帧数的增加而增加,这对于长视频生成来说是不太好的。
这篇工作希望能够实现在隐空间下利用运动动力学来实现视频生成模型的动态加速。这是基于如下观察:帧之间的运动特征在需要去噪步骤上面是一致的,特别是在粗粒度的前半段去噪过程中。这揭示了一种在一个视频帧上的噪声残差可以用到视频帧上的加速方式
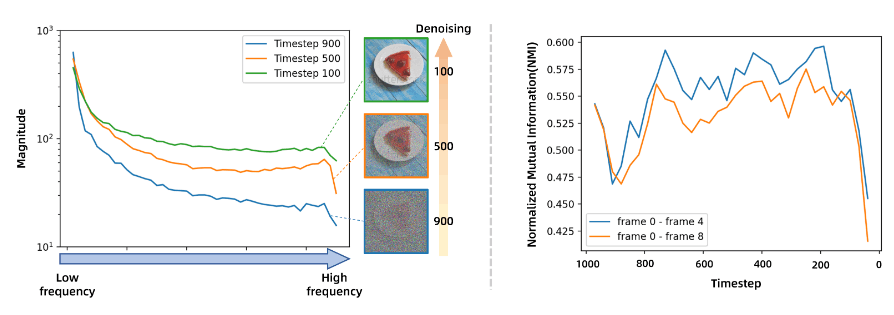
决定在哪个时间段使用也很重要,如果使用太早,则加速效果受限,如果使用太晚,则会影响图像生成的质量和效果。
为了缓解视频生成的计算资源负担,许多工作都使用基于 latent diffusion 的进行视频生成,比如LVDM 和 LaVie,但并没有对运动信息进行建模。
Latent-Shift 使用相邻帧的 feature maps 来促进运动信息的学习。
Text2Video-Zero 利用一个预先定义的方向向量来引入运动信息,但是在时间一致性上又出现了问题。
VideoLCM 利用教师-学生框架来蒸馏一致性,从而实现最小化步数的目的,但是它需要为每一帧 fine-tune 整个 diffusion 过程。
VidRD 也重用了之前生成的片段中的特征,但是并没有对整个视频序列去自适应地选择步数,限制了有效性。
发现:在大多数的去噪步骤中,运动信息是接近的,但是不同的帧序列中最优的重用步骤是不太相同的。从 1000 帧到 200 帧,重用结果的误差逐渐下降,表明了使用重用噪声残差应该是可行的。
使用隐空间残差表示特征的改变:
使用变换操作
从光流中获得启发,论文使用函数
NMI(Normalized Mutual Information),归一化互信息。
常用在聚类中,度量两个聚类结果的相近程度
他的值域是[ 0 , 1 ],值越高表示两个聚类结果越相似。归一化是指将两个聚类结果的相似性值定量到0~1之间。
互信息(mutual information)是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。简明的说就是,表示两个时间集合的相关性。
在论文中,两个运动矩阵的相似程度定义为:
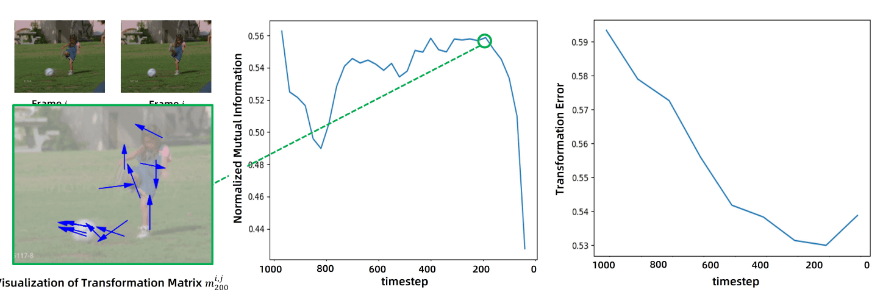
在 80% 的去噪过程中,数据表现出较高的 NMI 值和变换误差的下降,表明运动预测一致且可靠。这种一致性主要源于粗粒度、语义丰富的潜在特征的存在,这些特征增强了运动动力学的建模。其余20%的去噪过程中,更精细细节的出现增加了视觉特征的复杂性,导致NMI较低,可预测性下降
Dr. Mo 由两部分组成:the -Motion Transformation Network(MTN)和 Denoising Step Selector (DSS)。前者根据噪声残差得到对应步数的运动矩阵,向 DSS 提供运动序列及其一致性信息。后者则决定从那一步开始转为正常的去噪过程。
在推理过程中,从两个参考帧中提取不同时间步长的运动矩阵,DSS 对这些矩阵进行分析从而选择出最适合的
运动矩阵构建
最近的一些研究发现,从 U-Net 中提取的中间扩散特征可以捕获粗粒度和细粒度的语义信息,因此论文使用 Unet Decoder 中的特征来构建运动矩阵。
对于运动矩阵,首先从多个 block 中提取到不同尺度的特征,然后通过一个卷积层,然后计算余弦相似度,得到对应尺度的运动矩阵,最后再经过一个全连接层,构建出最终的运动矩阵。
由于大多数的扩散步骤中观察到的运动信息比较近似,因此可以使用一个运动矩阵作为从步数
优化目标
第一个 loss 是预测的残差和真实残差之间的 l1 loss
第二个 loss 是使用近似运动矩阵之后的产生的 loss,确保使用近似运动矩阵之后的效果和使用对应每一步的运动矩阵效果接近
第三个 loss 是确保时间一致性和能够尽可能准确预测之后的运动矩阵。具体来说是使用最近得到的 R 帧的运动矩阵,预测之后的 K 帧的运动矩阵。
最终的运动矩阵预测模块的 loss 为三者之和:
步数选择
DSS 是为了能够学习到一个
为了学习到
DSS 不需要评估完整序列,但可以通过仅分析可用数据的子集来有效优化